//Home
Broken systems in public…
General | Deron Grzetich | 9. July, 2013
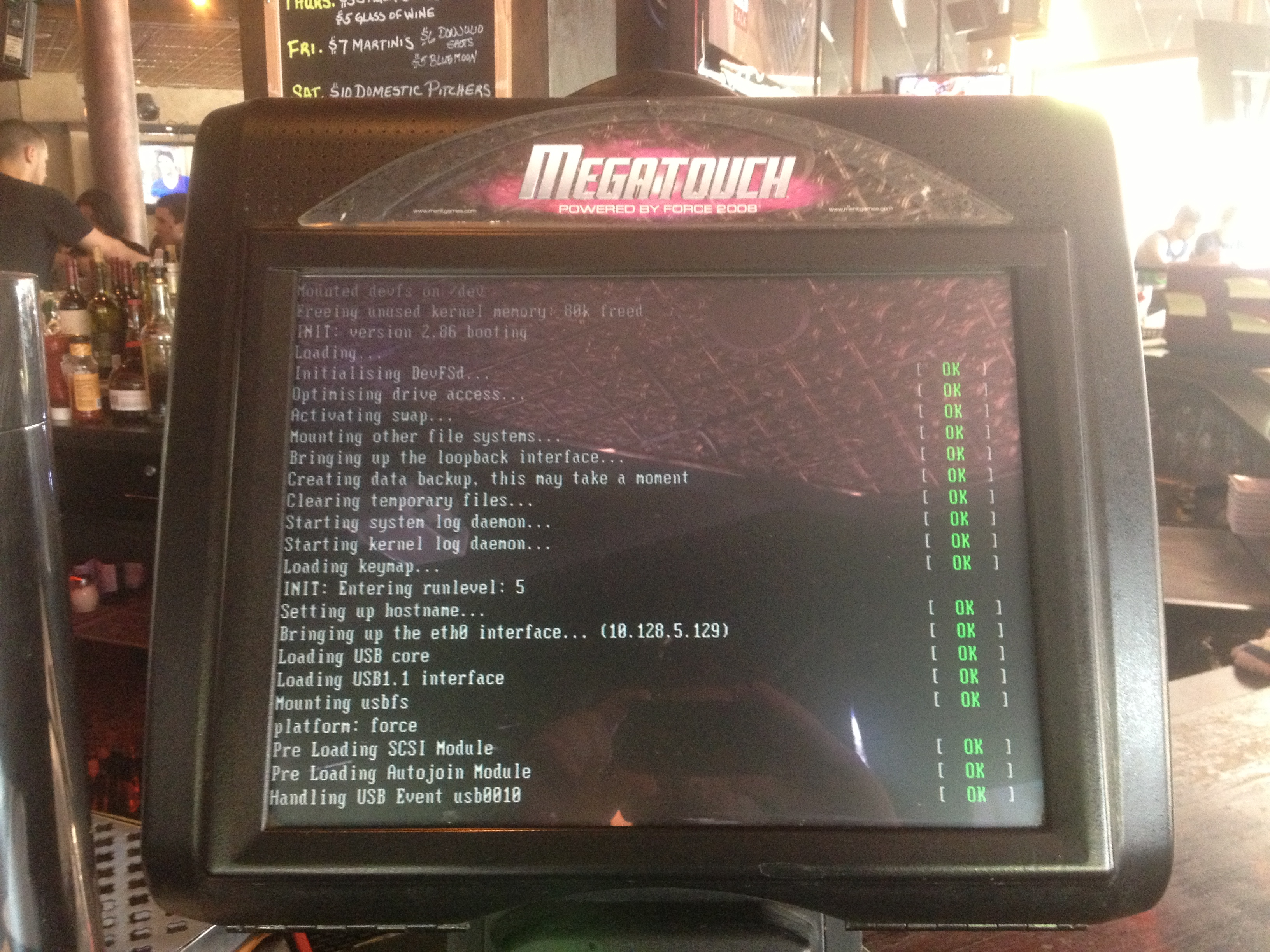
Since I don’t have time to actually write the articles I want to, I thought I’d add a post to share my collection of photos of broken systems. These are systems I find in public places, like hotels, airports, and grocery stores and I take a picture. So here’s my collection:
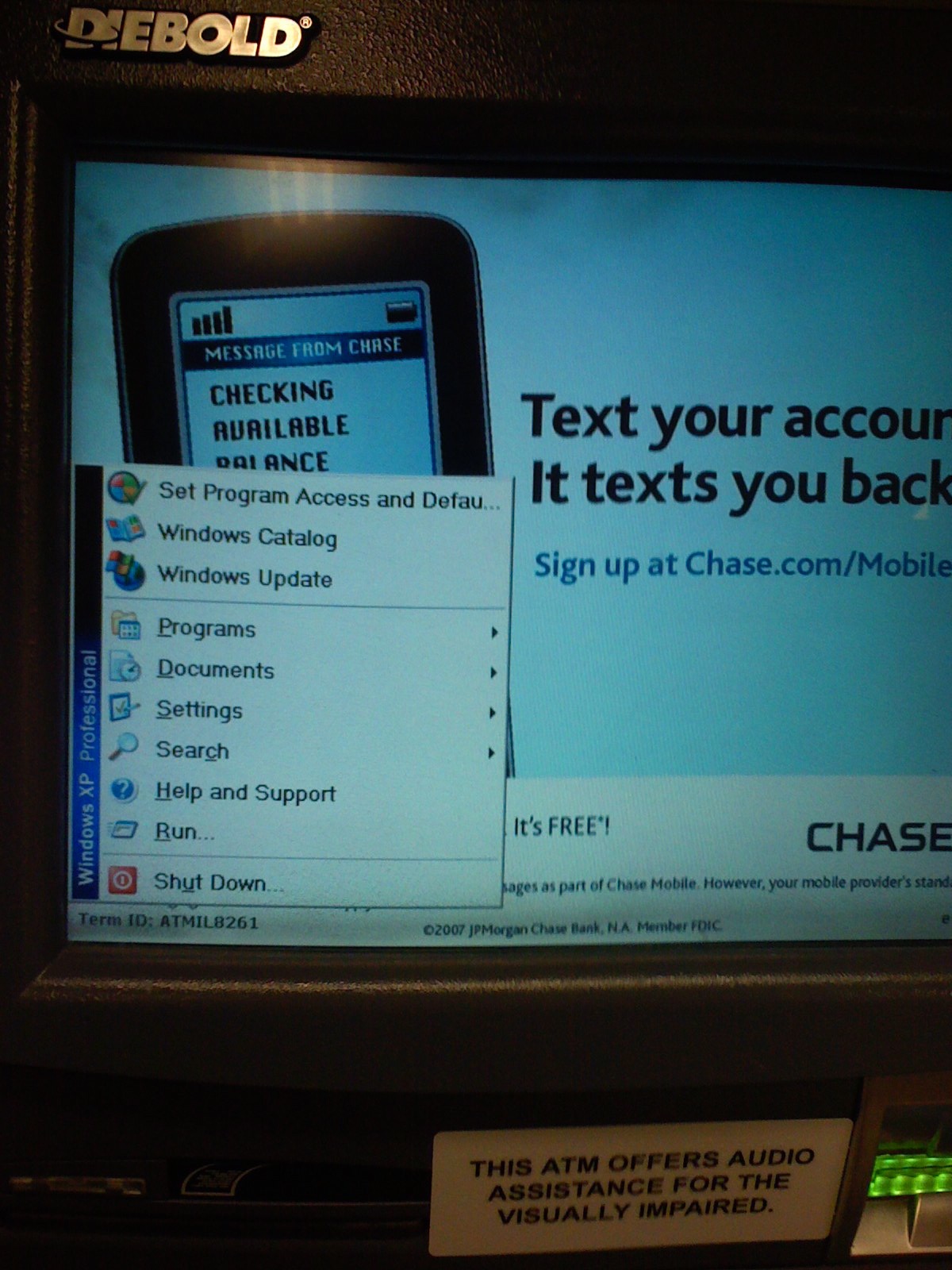
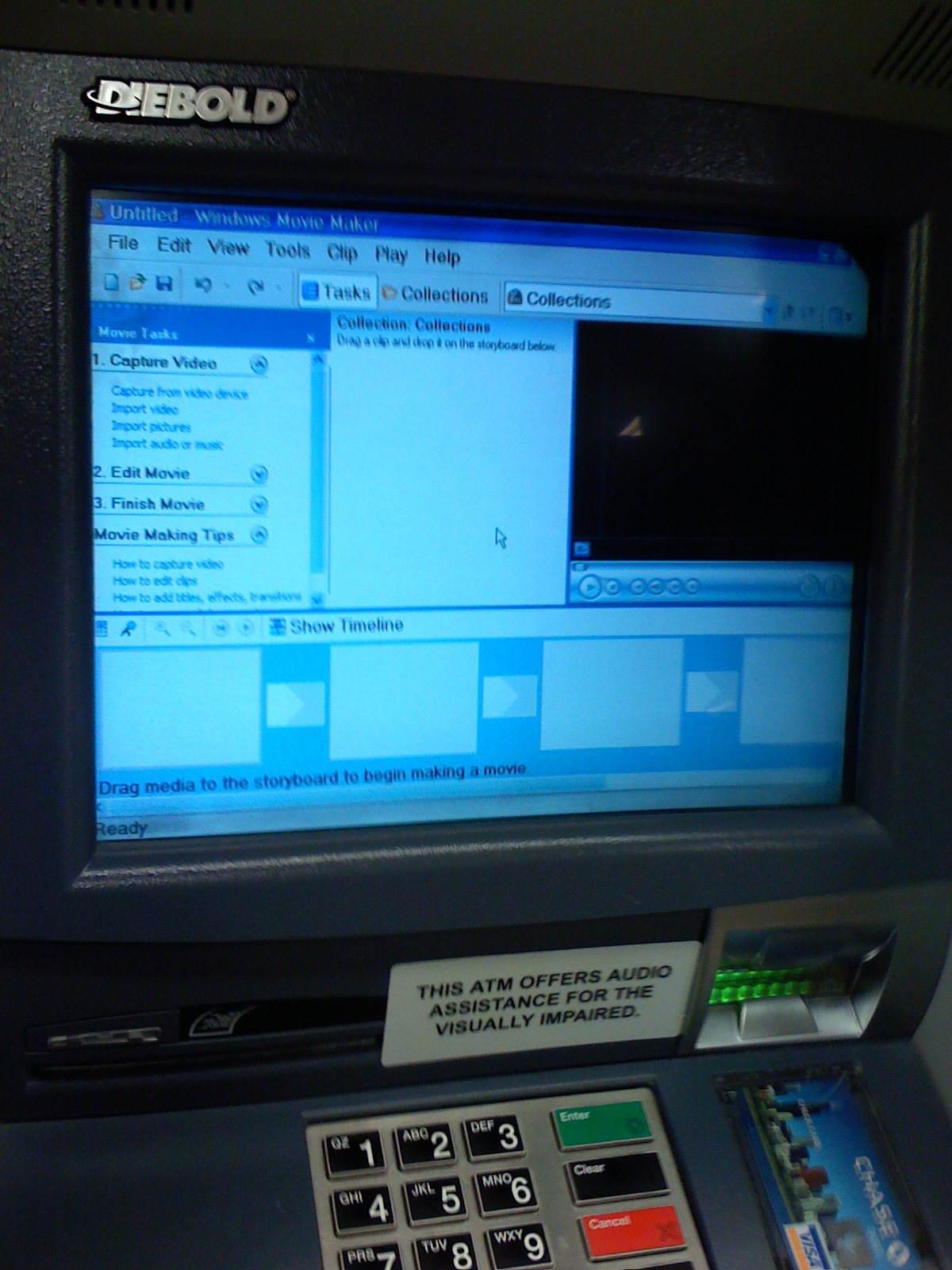
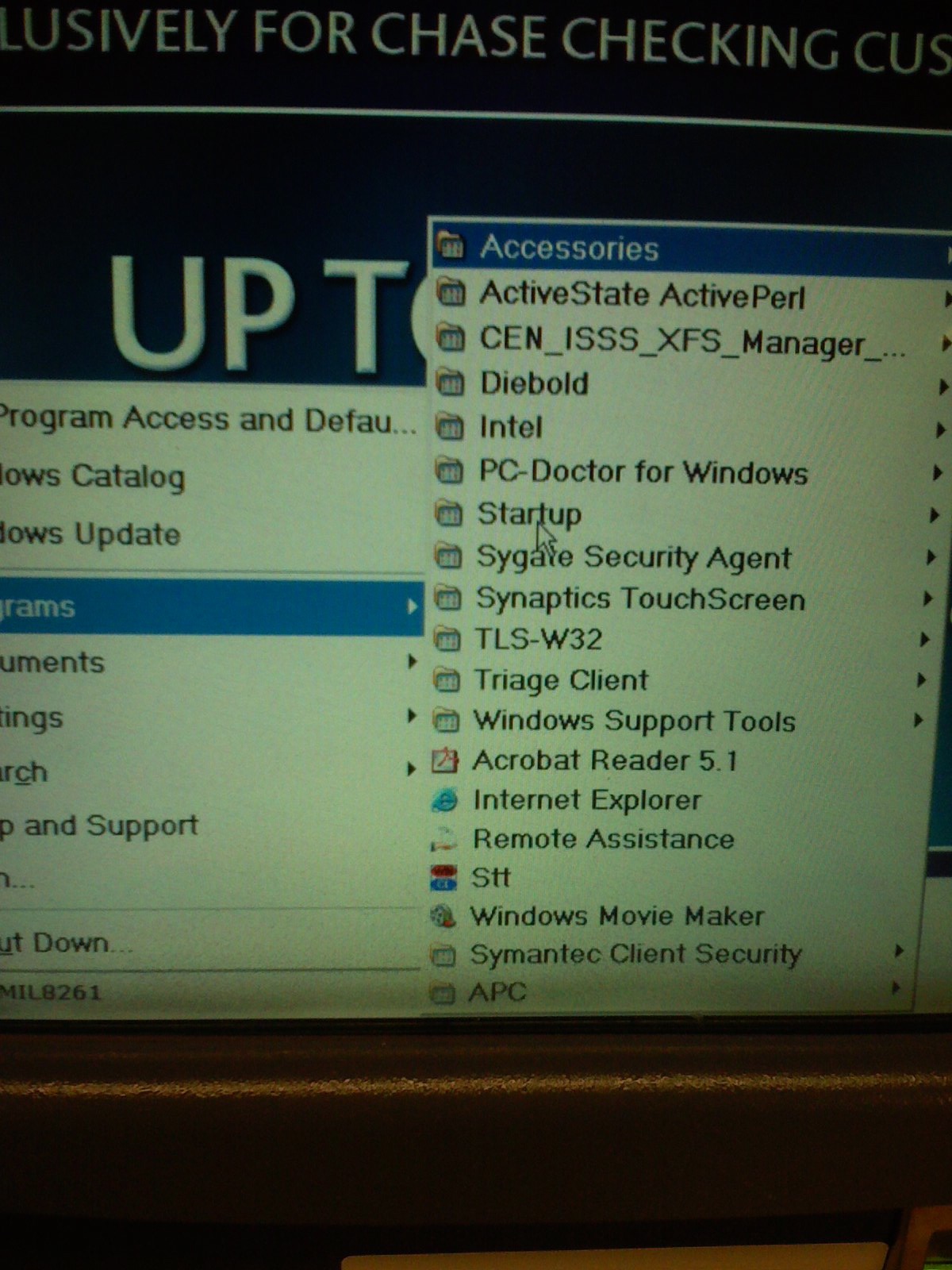
The photos above are pretty old, but as I was walking past the Chase ATM at the local Dominick’s I noticed that a start menu was displayed on the screen. And being curious I had to touch it to see what was installed. Oddly enough it had Windows Movie Maker, which I find to be a strange application to have installed on an ATM. Also curious that ActiveState Perl and Acrobat Reader were installed…would seem to me that the image for the ATMs was bloated.


Above is the airport collection, although I could swear that I had more of these…Flight notification screens, baggage claim, and an internet kiosk. By the way, who in the hell uses this system? I have a feeling this some sucker bought this in a “get rich overnight” scam where they “own” the system and sit at home and make it big! Suckers.

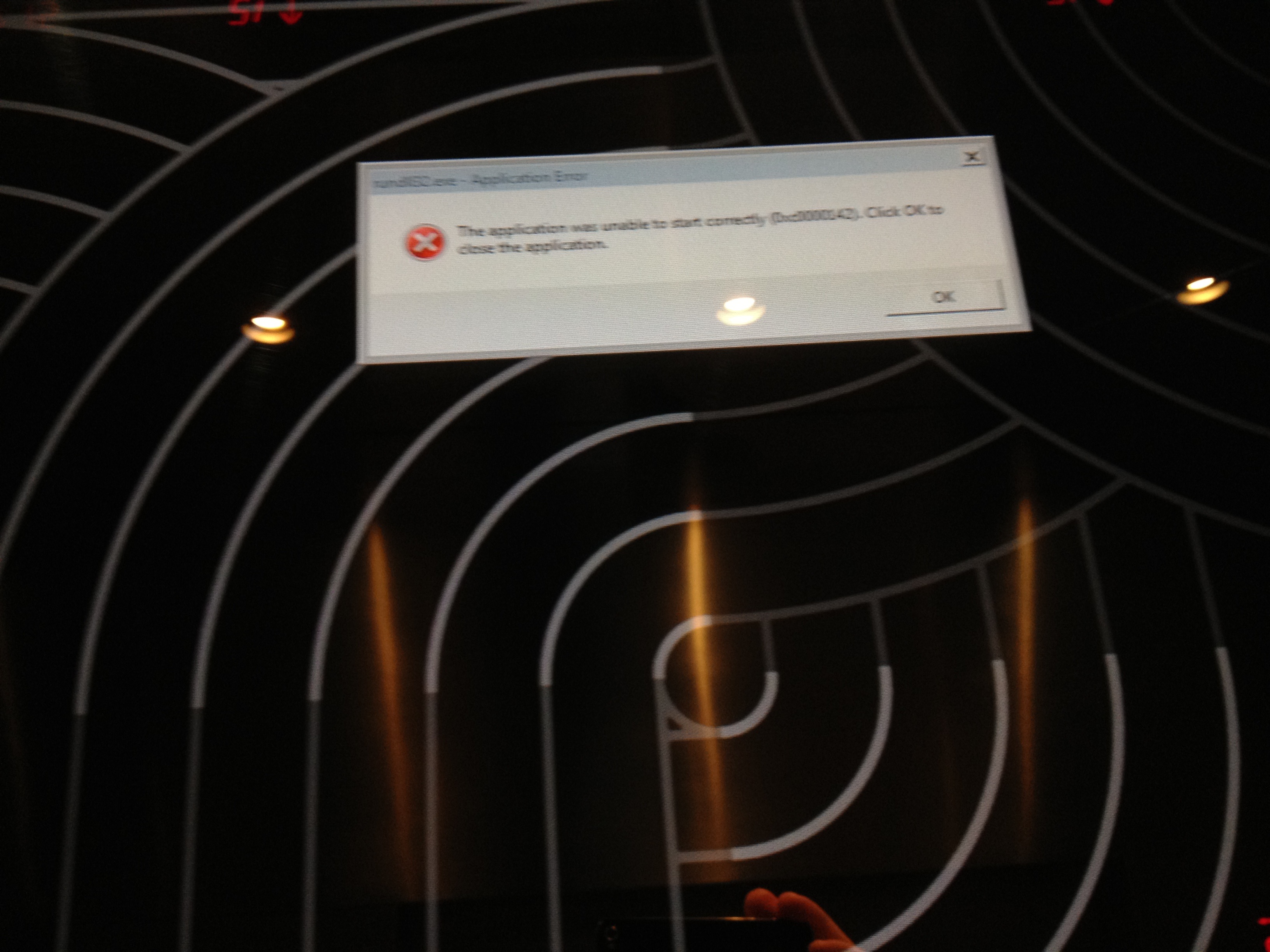
As much as I enjoy staying at the Cosmopolitan in Vegas they always seem to have an issue with that cool display system they run in the lobby, throughout the casino, and the elevators. The first one was just a licensing issue with the software, which I originally took so I could remember the name of the app. Surprisingly, it isn’t that expensive. The second photo is from the LCD screens in the elevator.
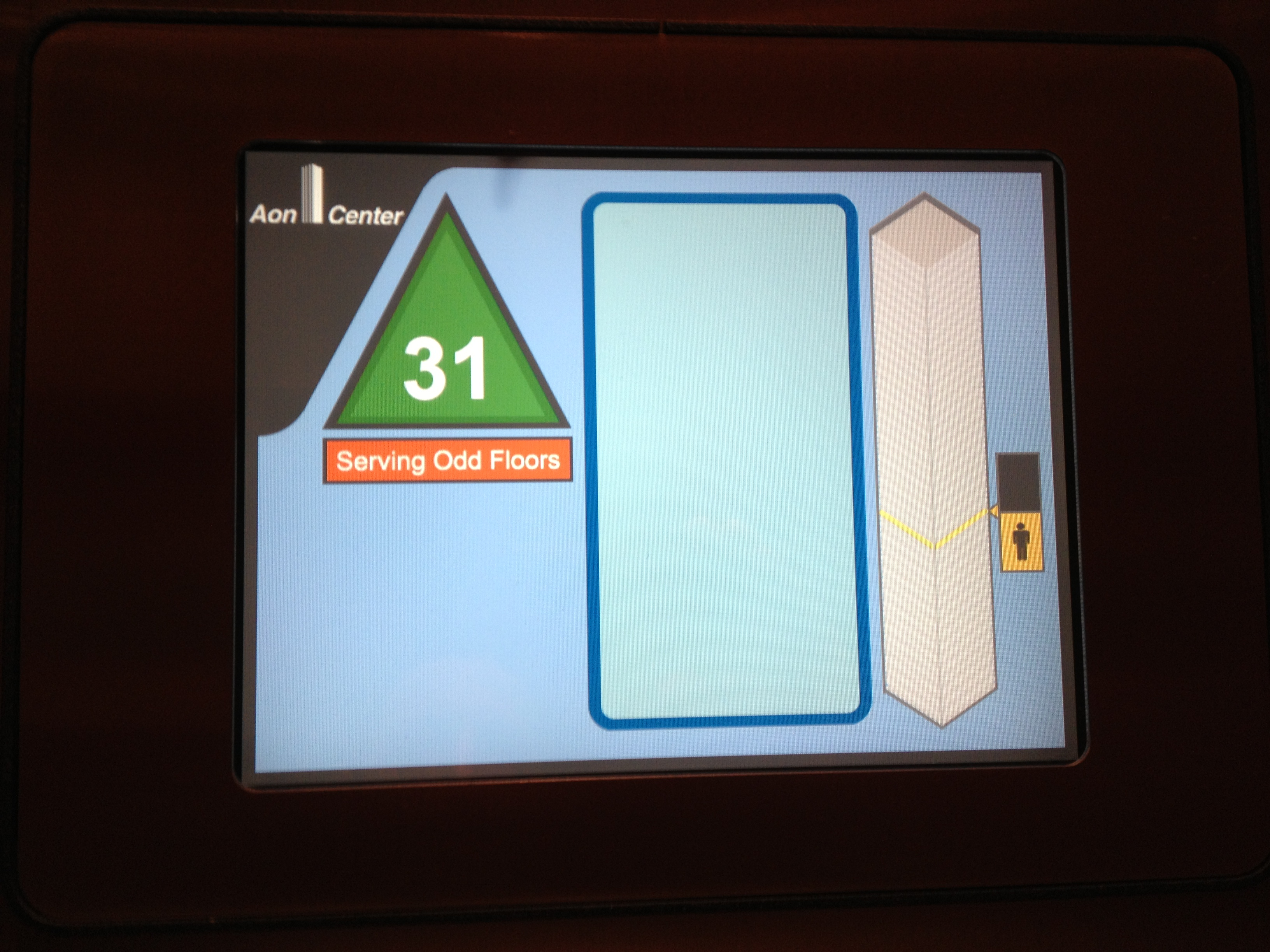
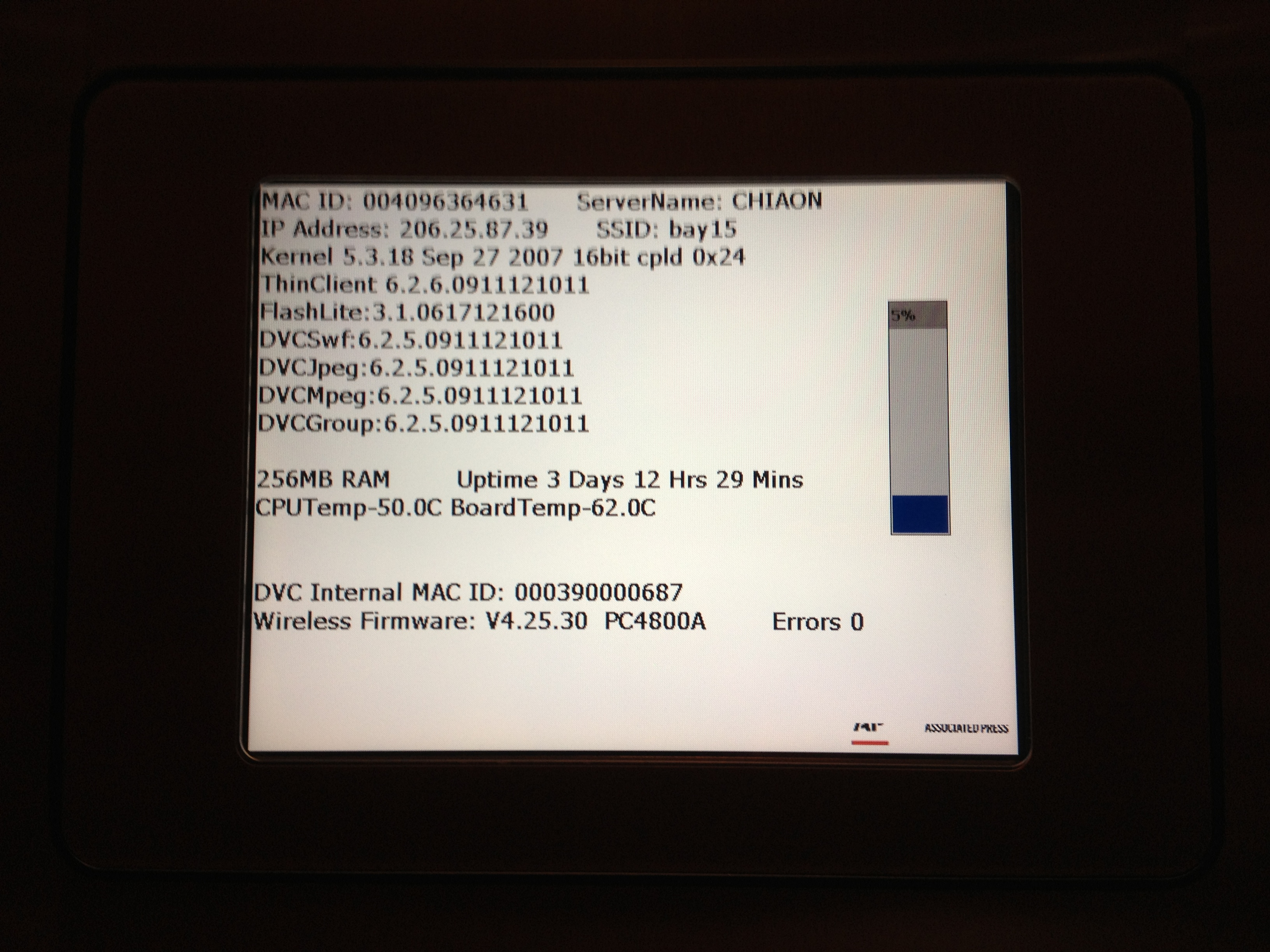
Keeping with the elevator track, the above two photos are from the elevators in the Aon Center where my office is…I think. I’m not really sure since I only go there once a month or so. I wasn’t sure if I should be worried if I’d get stuck in the elevator, but then I remembered that the screen on the left shows the “elevator” news so no one needs to make eye contact on the long elevator rides up to the 59th floor. Assuming that the IP is a true public then it comes back as owned by Savvis in Missouri somewhere just south of Chesterfield. Oh, and the kernel version is from 2007 and the SSID is bay15.
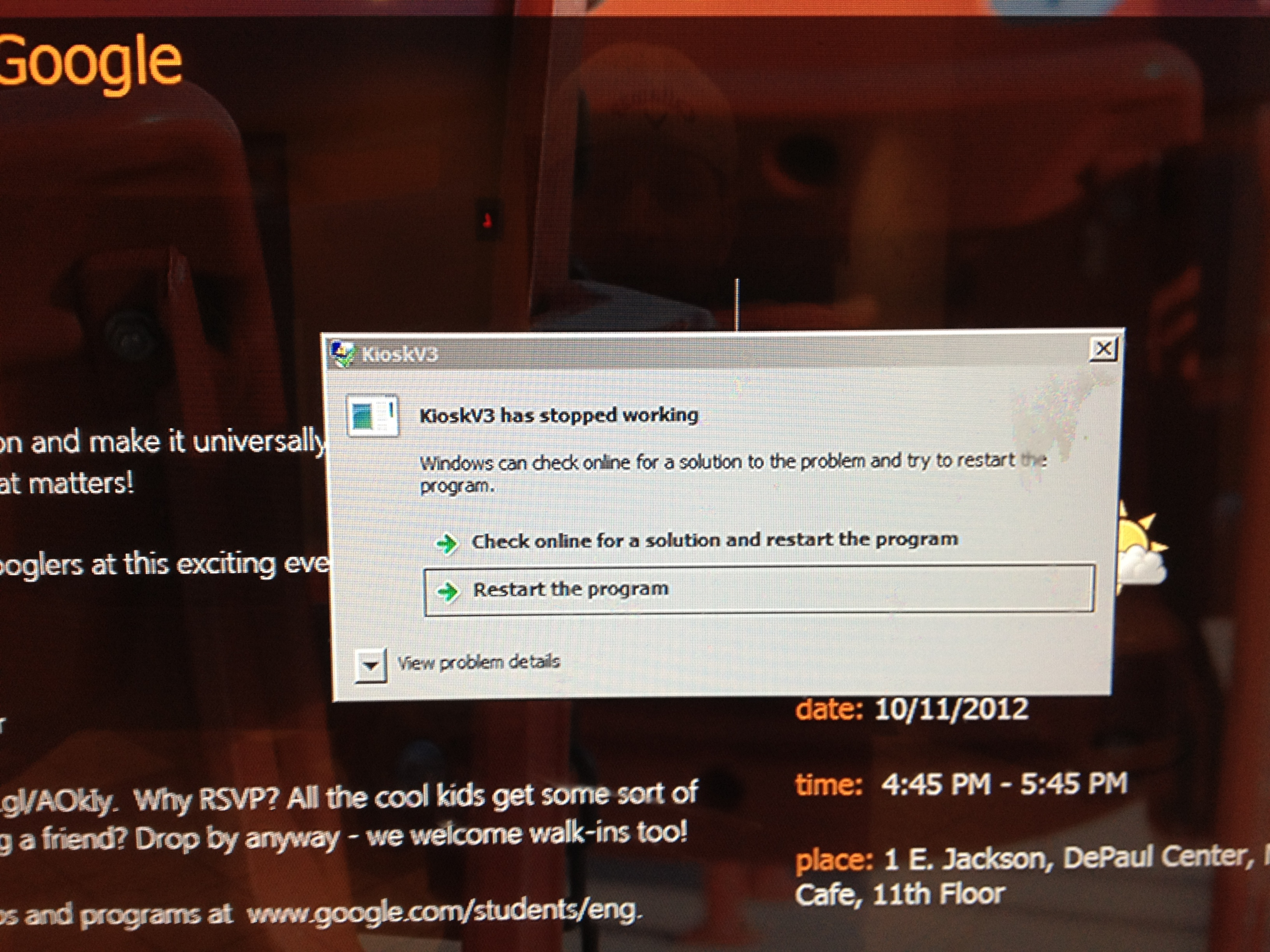

The last three are randoms. First is from DePaul University in the lobby where the app running the kiosk crashed…why? In the second one I think Best Buy needs to dispatch the Geek Squad, although this seems to be a Flash issue if watchdog.sys is causing the BSOD. Finally, a bar with a broken poker machine….running Linux.
JSPSpy demo
JSPSpy is an interesting tool that once uploaded to a server that supports JSP pages gives you a user interface on the web server itself. Its power comes from the ability to upload/download, zip, and delete files at will on the web server as well as spawn a command prompt. In addition, if you are able to gain credentials to a database server serving the web application (say through an unencrypted database connection string) it has a database connection component as well which would allow one to crawl a backend database server for information.
There is one issue with the code, which I find odd given that it was created in 2009, in that the SQL driver and URL for the connection using JDBC is incorrect. Well, not incorrect, the issue is that it supports SQL Server 2000. Starting with SQL 2005 the driver and URL were changed…and the code for JSPSpy which is easily accessible on the internet has an old connection string.
In addition, there are a few more UI’s for crawling a SQL backend using JSP floating around as well. I’ve included one in this demo as well.
The video demonstrates the power of JSPSpy in my demo environment consisting of Java 1.6, Tomcat 6.0, SQL 2005 and Windows 2003 Server. UPDATE: I updated the video on this as it appears it didn’t convert correctly and only shows in SD, not HD so the text is very hard to read. The new video below is in HD.
Has Human-based Malware Become a Commodity?
General | Deron Grzetich | 30. November, 2012
As a security professional it’s not often that people try to socially engineer me, especially over the phone. But, I thought the call I received was worthy of both a big laugh as well as a post. This got me thinking as well…is the going hourly rate for a person to sit and call people on the phone now low enough that it beats out automated malware and drive-bys? While I doubt that is the case I have to assume that since it is still a running scam, and I saw articles on this from August of this year, that they are making money. It also made me laugh as I took a trip down memory lane of having to do this as a consultant in a prior life, although I’d like to think my version was more convincing.
If you get it, here’s how the scam goes:
In my case it was a blocked call, and the person on the other end of the phone states they are with Microsoft. My guy’s name was Victor Dias (Indian accent) which didn’t quite make sense given his difficulty with spelling it when I asked. I’m kicking myself for not having a Win7 VM running at the time and following through on his instructions to see how this all ends, but I digress. He asked me to do some rudimentary things, such as go to Start, search for “ev”, and open the event viewer. Then he asked me if I have any errors or warnings in the Application logs, or if I have had any pop-ups stating that an application had crashed. Next, he asked if I had AV running (which of course I said no to) so he said “your computer is probably infected with the malwares (sp) and junks (sp), can you open Remote Assistance and allow me to connect so I can run a scan to remove the junks (sp)?”
Awesome! Going back to why I wanted to kick myself was that I didn’t have a Windows 7 system in front of me…I so wanted to see what he was going to do, and in hindsight what I may have been able to do to him (disclaimer: I’m not advocating offensive operations, wink wink). At this point I was done with the scam and started to ask him a series of questions. What is your name? Can you spell that? What is your MS employee ID number? BTW, he answered with 44398…ummm, pretty sure they are 6 digits and not 5, to which he said “oh yes, mine is 5 digits”. In fact, you can find this info online, so a little research prior to the scam never hurts (your welcome for the free advice, Victor). What finally broke him was when I asked where he was calling from. Manvil, TX, or Manville, TX…he couldn’t spell the name of the city he was in. Then I asked which major city in Texas was closest to his location…he couldn’t answer. So when I gave him options of cities he simply hung up, knowing he wasn’t getting anywhere with me.
So, I have a Win7 VM, my copy of NetWitness, and some surprises ready in case Victor calls back. Here’s hoping to hear from you, Victor.
DePaul ISACA Meeting on Zeus – Some Thoughts
General | Deron Grzetich | 11. November, 2012
I attended an ISACA presentation at DePaul the other evening given by Eric Karshiev from Deloitte on the Zeus malware family and had a few thoughts that I wanted to post (link to the event is at the end).
First, kudos to Eric for a decent presentation even though, self-admittedly, he hasn’t done much public speaking in his career….all I can say is that it only gets easier the more you force yourself to do it.
Second, while the presentation was at the right level of technical detail for an ISACA meeting, and I don’t mean that in a derogatory way ISACA, there were also some really good questions from the students in attendance, which was very encouraging. I do believe an important first step in defending your organization comes from a through understanding of the threats you face as well as your risk profile based on what your company does, how it does it, and your likelihood of being targeted by attackers in addition to the general opportunistic attacks we see on a daily basis.
That being said, I think there were some great questions that may not have been fully answered during the course of the presentation, and I’d like to list those here and take a shot at answering. I took the liberty of paraphrasing some questions and consolidating them where it made sense…so here we go:
1. What is the number one attack vector for malware in the recent past?
I made this question more broad and vague as was asked in the presentation, but I did that on purpose so I could answer it a few different ways. First, social engineering and targeting the users is nothing new, so that is has been and will be an attack vector that is used. More specifically, client-side browser exploits utilizing vulnerabilities in the browser, and more likely the plug-ins and 3rd party apps such as Adobe and Java (as an example, the new Adobe X 0-day that was, or will be, released soon). I think this has been standard operating procedure for attackers for the past 4 years given how insecure and under-patched many of these applications are. We are pretty good at patching the OS layer, but not so good at patching 3rd party applications, especially as they exists on mobile laptops that aren’t always connected to the corporate network. One thing to keep an eye on in this space is HTML5. If it ends up being as popular as Java/Flash look for an increase in vulnerability identification and use in attacks. Don’t believe me? Look at all of the exploit kits out there (last time I looked at my list I had 34 of them) and look at the CVE’s related to each of the exploit kits…they range from 2004-2011 and most target Java, Flash, and PDFs.
Want to see how insecure your 3rd party apps may be? Download and run Secunia PSI (free for personal use) and review the report.
2. Is Zeus targeted or opportunistic? Do I need to be more concerned about protecting a C-level exec, the rest of our users, or both?
Zeus, as a MITM banking Trojan, and by necessity is an opportunistic attack. If it can steal $5 or $5000 it doesn’t really matter. The more systems I have compromised the more money I can make, therefore from an attackers perspective it makes sense to spread this as far and wide as I can. I don’t mean to generalize here, but my advice is to protect all of your user’s systems in the same way when it comes to opportunistic threats. On the other hand, you do need to be concerned about targeted attacks against executives and ensure they, and their admins, understand that they may be targeted. For example, we trained the exec at the law firm to help them proactively identify a targeted phishing attack. One day we received a call from an exec stating that they received an email, it didn’t look legit, and had a PDF attachment that they didn’t open. We immediately reviewed the attached PDF and it was weaponized (although poorly) to infect the system with a dropper and connect back to C2 to get a binary. When we looked at the content of the email message we noticed that it was unique enough to comb through all received mail message for the same email and attachment. What we noticed was that 5 other messages like the one we had in our possession were sent, but only to executives of the firm. On top of that, each had a weaponized PDF attachment that was different from the others but had the same dropper functionality. The polymorphism was likely in place to evade IDS, mail filters, and AV…all of which were bypassed without issue.
3. You said AV isn’t effective given that it is signature based. What else can we do to protect users from being infected, and if we can’t protect them how can we detect malware?
This was a great question, and the one that actually spurred me to write this post, that went unanswered (at least to my satisfaction). Yes, part of AV detection is signature based, but so are mail filters and IDS/IPS systems. It is true that these commodity controls can protect us from the “known” malware that is floating around the internet, but it can’t protect us from new malware…I think this is an obvious statement given the number of systems that are compromised on a regular basis.
That being said, there are some controls we can implement that aren’t signature based that can detect malware based on behavior. Since I mentioned social engineering, it may be helpful to give our users a hand in determining the “goodness or badness” of emails they receive by ranking them. Email analytics is a good start, and products have now sprung up that play in this space. ProofPoint is an example of a tool that may empower your users and allow them to make better decisions about emails they receive and what to do with them. It isn’t full-blown security data analytics, but it is a start. Another example of a vendor in this space is FireEye with their email and web products, which can identify executable attachments in email and those received from clicking on internet links (or drive-by downloaded), analyze them in a sandbox, and make a determination of the as to their “badness”. Damballa is also another product focused on behavior analysis of malware as it uses the network…this makes sense as malware which doesn’t communicate to its owner isn’t very valuable. Their technology makes use of the known C2 systems as well as DGA-based malware generating many resolution requests and getting a bunch of NX’s back. Finally, Netwitness is an invaluable tool in both monitoring and incident response as it gives the visibility into the network that we have been lacking for so many years. And yes, there is a lot of overlap in these tools, so expect some consolidation in the coming years.
I don’t mean to push vendors as a solution and would never throw technology at a situation to fix the underlying root causes – unpatched OS, browsers, and 3rd party applications open a nice attack surface for the bad guys. Why do we allow our users full control of their system? Do they all need to be admin? We also don’t seem to be doing a great job of monitoring the network and all of the systems we own…what bothers me most is that the attackers are attacking us on home turf. We own the battlefield and keep getting our a$$es handed to us.
4. There was a comment on the use of Palo Alto and Wildfire in relation to the use of the cloud and how that may help.
Most all of the technologies mentioned above use the same mechanism, and this is nothing new as AV vendors have been doing this since they realized they could get good intel from all of their customers. My only caution is that the benefit realized from sending all bad binaries to a cloud service for analysis is that it is dependent on how good that analysis is.
So to close, my suggestion to anyone interested in malware prevention, detection, and analysis is that there are some great resources on the internet as well as some decent classes you can take to better understand this threat. If analysis is your thing then I’d recommend Hacking – The Art of Exploitation and Practical Malware Analysis as some good reads. Setup a lab at home and experiment with some of the tools and techniques used by past and current malware…nothing beats hands on work in this space as the more you know the better you are at malware identification and response.
Link to the presentation site – http://events.depaul.edu/event/zeus_malware_family_the_dark_industry#.UJ1baoXLDEs
OK, maybe you should do more than tap your network before an incident…
General | Deron Grzetich | 19. September, 2012
In looking back at the last post about tapping your network prior an incident I thought to myself, why did I stop there…or more appropriately, why was I focused on having the right infrastructure in place? Perhaps it was out of frustration of showing up to a client and wondering why it was so difficult to start quickly monitoring the environment to get a handle on the issue we may, or may not, be dealing with. But when I thought about it what I really needed was a Delorean with a flux capacitor and a crazy Doc Brown of my own so I can travel back in time (no, I don’t own a vest jacket or skateboard but may on occasion rock some Huey). I don’t have a time machine and can’t go back in time, but what I can do is make some recommendations that we start capturing information that may be useful in an incident response PRIOR to one happening. I don’t mean to dismiss the ability to rapidly scale up your monitoring efforts during a response, even if that means dropping new tools into the environment or calling on 3rd parties to assist, but would be doing an injustice if I didn’t discuss what you should be collecting today.
Normally I’d be frustrated with myself for recommending that you collect information, logs, data, etc. and then do nothing with them. But, is that really a bad thing? I thought back to when I started at the law firm and many years ago when I asked what we monitored I was told we had network perimeter logs and that they were being sent to an MSSP for storage. Were we doing anything with these logs? No. Was the MSSP doing “some science” to them and telling us bad things may have been happening? No. So, at first I questioned the value, and sanity, of the decision to capture but do nothing with our information. But the more I thought about it the more I understood that IF something had happened I would/may have the information I need to start my investigation. Forensics guys may know this as the concept of the “order of volatility”, or how quickly something is no longer available for analysis. I’d say besides system memory that network connections would be very high up on that list. And if I weren’t at least capturing and storing these somewhere then they would be lost in the past because of their volatility. So, it isn’t that bad to just collect data, just in case.
I’d also like to temper the aspirations of folks who want to run out and log everything for the sake of logging everything. What I’d much rather see is that your logging and data collection be founded on sound principles. What you choose to focus on should be based on your risk, or what you’re trying to protect/prevent, and I hope to highlight some of this in the rest of this post. As an example, if you are logging successful authentications, or access to data it should be focused on your most valuable information. This will, for obvious reasons, vary from organization to organization. A manufacturing company is more likely trying to protect formulas, R&D data, plant specifications and not medical records like an organization in healthcare would. OK, on to the major areas of logging to focus on, or at least something to consider:
Perimeter/Network Systems
- Firewalls
- Web proxies
- Routers/switches (netflow)
- DHCP/DNS
Application/Database
- Access to sensitive data via applications
- Database administrative actions/bulk changes
- Administrative access to DBs, applications, and systems (focus on critical systems first)
- SharePoint and other data repository access
- Email systems
Security Controls
- IDS/IPS
- AV, Anti-malware, and end-point controls
- File integrity monitoring systems
- DLP and data loss prevention tools
Contextual Information
- Identity management systems and access governance systems
- Vulnerability information
- Operational data such as configuration information and process monitoring
And as Appendix A.2.1 of NIST 800-86 says, have a process to collect the data that is repeatable and be proactive in collecting data – be aware of the range of sources and application sources of this information.
While I realize the recommendations of this post are rather remedial, I still find organizations who haven’t put the right level of thought into what they log and why. Basically, the recommendation I may make is to first understand what you may log today, identify gaps in the current set of logs and remediate as necessary, and design your future state around a solid process for what you plan to collect and what you plan to do with it. More to come…
Tap Your Network BEFORE You Have an Incident
In responding to incidents there is one thing that stands out that I felt deserved a post and that is the topic of network taps and visibility. While some large companies often have the necessary resources (i.e. money, time, engineers, other tools which require visibility into network traffic, etc.) to install and maintain network traffic taps or link aggregators, the number of companies I run into without ANY sort of tap or aggregator infrastructure surprises me. While it depends on the type of incident you’re dealing with, it is quite often the case that you’re going to want, better yet need, a very good view of your network traffic down to the packet level.
If you’re not convinced imagine this scenario: During a routine review of some logs you see that you have traffic leaving your US organization which is going to an IP address that is located somewhere in Asia. It appears to be TCP/80 traffic originating from a host on your network, so you assume it is standard HTTP traffic. But then you remember that you have a web proxy installed and all users should be configured to send HTTP requests through the proxy…so what gives? At this point your only hope is to view the firewall logs (hopefully you have these enabled at the right level), or you can go out and image the host to see what sites it was hitting and why. But, if you had packet level inspection available a simple query for the destination and source address would confirm if this is simply a mis-configured end user system, a set of egress rules the firewall that were left behind that allow users to circumvent the proxy, or if it is C2 traffic to/from an infected host on your network.
Having taps, SPAN/mirror ports, or link aggregators in place PRIOR to an incident is the key to gaining visibility into your network traffic, even if you do not possess the monitoring tools today. It allows response organizations to “forklift” a crate of tools into your environment and gain access to the network traffic they need to begin the investigation. The main benefit of tapping your infrastructure prior to an incident is that you don’t need to go through an emergency change control at the start of the incident just to get these taps, SPAN, or aggregators installed. This is also technology that your network team may not be familiar with configuring, installing, or troubleshooting. So setting up your tapping infrastructure up front and being able to test it under non-stressful conditions is preferred. That being said, it is also important to remember that there are pros and cons on how you pre-deploy your solution, both in terms of technology and tap location.
A couple of questions should be answered up front when considering how to approach this topic:
- Can our current switching infrastructure handle the increased load due to the configuration of a SPAN or mirror port?
- Will we have multiple network tools (i.e. Fireeye, Damballa, Netwitness, Solera, DLP, etc.) that need the same level of visibility?
- If we tap at the egress point what is the best location for the tap, aggregator, or SPAN?
- Do we know what traffic we are not seeing and why?
Taps vs. Link Aggregators vs. SPAN/mirror
The simplest way to gain access to network traffic is to configure a switch, most likely one near your egress point, to SPAN or mirror traffic from one or more switch ports/VLANs to a monitor port/VLAN which can be connected to the network traffic monitoring tool(s). The downside of SPAN ports is that you can overwhelm both the port and/or the switch CPU depending on your hardware. If you send three 1G ports to a 1G SPAN port, and the three 1G links are all 50% saturated at peak, you will drop packets on the SPAN port shortly after you surpass the bandwidth of the 1G port (oversubscription). The safest way to use a SPAN in this case is to mirror a single 1G port to a 1G mirror port. Also consider how many SPAN or mirror ports are supported by your switching hardware. Some lower end model switches will only support a single mirror port due to hardware limitations (switch fabric, CPU, etc.), while more expensive will be able to support many more SPAN ports. I’m not going to get into local SPAN vs. RSPAN over L2 vs. ERSPAN over GRE…that is for the network engineers to figure out.
Passive and active taps can alleviate some of the issues with dropped packets on a switch SPAN as they sit in-line to the connection being tapped and operate at line speed. The drawback is they may present a single point of failure as you now have an in-line connection bridging what is most likely your organization’s connection to the rest of the world. Also, keep in mind that passive taps have two outputs, one for traffic in each direction so you’ll need to ensure the monitoring tools you have or plan to purchase can accept this dual input/half duplex arrangement. Active taps on the other hand are powered so you’ll want to ensure you have redundancy on the power supply.
The last type of tap isn’t really a tap at all, but a link aggregator which allows you to supply inputs from either active/passive taps or switch SPAN ports which are then aggregated and sent to the monitoring tool(s). The benefit of an aggregator is that is can accept multiple inputs and supply multiple monitoring tools. Some of the more expensive models also have software or hardware filtering, so you can send specific types of traffic to specific monitoring tools if that is required.
Last but not least are the connection types you’ll be dealing with. Most monitoring tools mentioned in this post accept 1G copper up to 10G fiber inputs, depending on the tool and model. You also need to make sure your taps and/or aggregators have the correct types of inputs and outputs that will be required to monitor your network. If you’re tapping the egress point chances are you’re dealing with a 1G copper connection, as most of us rarely have a need for more than 1G of internet bandwidth. If you’re tapping somewhere inside your network you may be dealing with 1G, 10G, or fiber connections or a combination (i.e. 10/100/1000 Base-T, RJ-45 Ethernet, 1000 Base-Sx/Lx/Zx Ethernet multimode or singlemode), so keep this in mind as you specify your tapping equipment.
Location – Outside, Inside, DMZ, Pre or Post Proxy? What About VM Switches?
Next is the issue of location of the network tap and the answer to this really depends on what level of visibility you require. At a minimum I’d want to tap the ingress/egress points for my network, that is any connection between my organization and the rest of the world. But that doesn’t quite answer the question as I still have options such as outside the firewall, directly inside the firewall (my internal segment), or just after my web proxy or IPS (assumes in-line) or inside the proxy.
There are some benefits and drawbacks to each of these options; however I’m most often interested in traffic going between my systems and the outside world. The answer mainly depends on your network setup and the tools you have (or will have) at your disposal. If you tap outside the firewall then you can see all traffic, both traffic which is allowed and that which may be filtered (inbound) by the firewall. The drawback is both noise and the fact that everything appears to originate from the public IP address space we have as I’m assuming the use of NAT, overload NAT, PAT, etc. is in use in 99% of configurations. The next point to consider is just inside the firewall; however that depends on where you consider the inside to be. If we call it the inside interface (that which our end users connect through) then I will gain visibility into traffic pre-NAT which shows me the end-user’s IP address, assuming an in-line (explicit) proxy is not being used which would then make all web or other traffic routed through the proxy to appear to originate from the proxy itself. Not forgetting the DMZ, we may also tap our traffic as it leaves the DMZ segment as well through a tap or SPAN as that will allow for monitoring of egress/ingress traffic but not inter-DMZ traffic.
Pre or post-proxy taps need to be considered based on a few factors as well. If it is relatively simple to track a session that is identified post-proxy back to the actual user or their system, and is it cheaper for me to tap post-proxy, then go for it. If we really need to see who originated the traffic, and what that traffic may look like prior to being filtered by a proxy, then we should consider tapping inside the proxy. In most situations I’d settle for a tap inside the proxy, just inside the firewall prior to NAT/PAT, and just prior to leaving the DMZ segment. To achieve this you may be looking at deploying multiple SPANs/taps and using a link aggregator to aggregate the monitored traffic per egress point.
Finally, what about all the virtual networking? Well, there are point solutions for this as well. Gigamon’s GigaVue-VM is an example of new software technology that is allowing integration with a virtual switch infrastructure. While this remains important if we need to monitor inter-VM traffic, all of these connections out of a VM server (i.e. ESXi) need to turn physical at some point and are subject to the older physical technologies mentioned above.
Limitations
This should be a standard section on encryption and how it may blind the monitoring tools. Some tools can deal with the fact that they “see” encrypted traffic on non-standard ports and report that as suspicious. Some don’t really care as they are looking at a set of C2 destinations and monitoring for traffic flows and amounts. If you’re worried about encryption during a response you probably should be…and if you’re really concerned consider looking into encryption breaking solutions (i.e. Netronome). Outside of the encryption limitation, after you deploy you tapping infrastructure your network diagrams should be updated (don’t care who does this, just get it done) to identify the location, ports, and type of component of your solution along with any limitations on traffic visibility. Knowing what you can’t see in some cases is almost as important as what you can see.
Final Thoughts
Find your egress points, understand the network architecture and traffic flow, decide where and how to tap, and deploy the tapping infrastructure prior to having a need to use it…even if you don’t plan on implementing the monitoring tools yourself. This is immensely beneficial to the incident responders in terms of gaining network visibility as quickly as possible. As time is of the essence in most responses, please don’t make them sit and wait for your network team to get an approval to implement a tap just to find out they put it in the wrong place or it needs to be reconfigured.
If this needs to be sold as an “operational” activity for the network team, tapping and monitoring the network has uncovered many mis-configured or sub-optimal network traffic flows. Everything from firewall rules which are too permissive to clear text traffic which was thought to be sent or received over encrypted channels. Something to keep in mind…who knows, if you ever get around to installing network-based DLP you’re already on your way as you’ll have tapped the network ahead of deployment.
Cyber Security Experts?
General | Deron Grzetich | 17. May, 2012
Reading an article on nbcchicago.com titled “Experts Warn Laptops Could Be Targeted During NATO Summit” made me laugh…specifically this quote, “The chief technology officer at SRV Network Inc. in Chicago told the Sun-Times computer users should make sure their anti-virus software is updated”. Really? Sure, if you want to protect yourself against commodity malware that has been floating around for some time…it still amazes me that so-called security experts make this recommendation. Don’t get me wrong, it is a very safe recommendation to make and I don’t mean to imply that you shouldn’t run updated antivirus. What I don’t think this statement conveys is that there is malware that can be built, easily and inexpensively, that bypasses your antivirus control regardless of how “up-to-date” the signatures may be. I hate that these statements give many people a false sense of security…”Oh, nothing can happen to me, I have antivirus enabled and it is up-to-date”. Maybe it was the brevity of the article in this case that got to me, but I’d probably make some better recommendations here, including:
- Update both the operating system you use as well as any applications and browser plug-ins from a known good internet connection (from a connection you own).
- Harden the system, disable unnecessary services and remove unnecessary applications.
- Consider disabling scripts in your browser, using the No-Script plug-in for Firefox as an example.
- Disable services with listening ports where possible. For example, in Windows, there is no need to run file and printer sharing on a laptop, so turn it off.
- Consider using a host-based firewall which will limit network borne attacks against your system.
- Connecting to “known” wireless networks is a start, but nothing guarantees that you’re actually connecting to a “good” access point. It is fairly trivial to run a fake access point and proxy connections, so on that note:
- Turn off beaconing so your system isn’t actively looking for and connecting to access points on your behalf. As an attacker I can use these beacons to then setup a fake access point you’ll automatically connect to.
- If you own the WiFi access point you’re connect to it is trivial to verify the MAC address of the AP you’re connecting to, do it.
- If you do connect to an “open” access point you should consider using a VPN connection to encrypt the wireless traffic. Using SSL/TLS is no longer a guarantee given side jacking tools like Firesheep.
- Don’t assume a WiFi network you setup for a bunch of people to use is “unhackable”. Many tools exist to break WPA-PSK and it gets worse if you’re running a router that is vulnerable to WPS pin attacks. if you’re running WPA-Enterprise then I’m impressed.
- If you’re really paranoid, you can throw a VPN, VPS and ToR into the mix as well and run the traffic destined for the internet securely through another system in another country. Ever see that big data center someone is building in Utah? How about orange doors at AT&T? Paranoid yet?
- All this talk of WiFi, why not just bust out a 4G hotspot instead…protected of course.
- If you’re extremely paranoid how about running a throw-away system or a something off of a live disk like BT5?
- Finally, practice restraint in your browsing…don’t click yes to everything without reading, take certificate errors seriously, and try not to get caught up in the excitement.
I do realize some of my recommendations above may be over the average user’s head, but we need to do better than making a blanket “update your antivirus” statements if we really want to empower users or assist them in protecting themselves. I also think if you search there is probably a guide, better than what I typed up in 10 minutes, posted somewhere online that you could use.
All of the above makes no mention of “why” someone would want to break into users laptops. Sure, there will be a lot of people around using WiFi and mobile data networks and such to connect, share, post images, video, stories, etc. I’m just not seeing how this is any different from any other situation, such as travelling and connecting to a hotel’s WiFi network, or at the airport, or even as I sit here on my own network at home. Point is, you’re being attacked every day regardless of where you are, so I just don’t get why we are making a big deal out of this because we added NATO to the title.
I’m cranky and need more coffee…
2012 North American CACS Conference
General | Deron Grzetich | 6. May, 2012
I’ll be speaking at the North American CACS Conference for ISACA in Orlando, FL on May 7th. I’m on a panel discussing Emerging IT Risks @ 10:15am and @ 3:30pm I’m presenting on Auditing Mobile Computing.
Update on Ethically Teaching Ethical Hacking
General | Deron Grzetich | 4. May, 2012
I have to give DePaul University some kudos on this topic. They came around and added my course to the regular course catalog for the Computer, Information, and Network security program as CNS388/488 – Security Testing and Assessment. It is a foundational level course on ethical hacking, the methodology, and the tools used in these types of assessments. I’m happy to see that some schools are coming around and it will be available in the coming Fall quarter.
RSA/EMC Webinar on Security Resilience
I also presented on a RSA/EMC webinar on security threats and building the right controls back in January that I never posted. The link to the event is Here.